
Typical test run (if not specified): 4+50 particles, timestep = 20 days,
stop time = 0.2 Myr. (The initial conditions were the same as in
eos-j94_1.)
You can also see a(t) plots
for individual runs (all look very similar, as they should).
| run directory | run-time [sec] | notices |
bsy_g77 |
10822 |
Bulirsch-Stoer integrator (with Yarkovsky subroutines) is approx. 7 times slower than RMVSY.
rmvsy_g77 |
1652 | g77-0.5.24 |
rmvsy_omf77 |
1496 | Omni-1.3 (http://phase.etl.go.jp/Omni/) |
rmvsy_fujitsu |
1371 | Fujitsu F95 (compiled by Menios Tsiganis) |
rmvsy_lf95 |
1147 | Fujitsu/Lahey F95 Express 6.0 |
rmvsy_pgf90 |
1133 | Portland group Fortran90 (1164 sec with -mp on 1 CPU) |
Compiler omf77 is faster than g77 by approx. 10 %. Fujitsu/Lahey and Portland group compilers beat g77 by approx 30 %.
http://sirrah.troja.mff.cuni.cz/~mira/mp/
for downloads. The specification of OpenMP http://www.openmp.org.)
rmvsy_omf77_ida1 |
1857 | run only on 1 CPU |
rmvsy_omf77_ida2 |
1263 | 2 CPUs (SMP architecture) |
On two processors the RMVSY is (only) 1.5 faster than on single one.
mvsy_omf77_ida1 |
1613 | run only on 1 CPU (50 TPs) |
mvsy_omf77_ida2 |
1044 | 2 CPUs (SMP architecture) |
mvsy_omf77_ida1_1 |
846 | 1/2 of TPs |
mvsy_omf77_ida500_1 |
1537 | 1 CPU, NTP = 500, tstop = 0.02 Myr |
mvsy_omf77_ida500_2 |
945 | 2 CPUs |
MVSY is only 1.2 times faster than RMVSY due to Yarkovsy part of the code (as compared to factor 2 between pure MVS and RMVS3).
On 2 CPUs the integration takes 1.55 times shorter time span. (In case of 10 times larger number of TPs, ie, 500, the ratio is even slightly better: 1.62.)
When you manually split the run into two pieces and run two separate jobs, it will take 1.9 shorter time than single run on 1 CPU.
(It means: you loose 20 % of computation speed on 2 CPUs, compared with 2 single runs, but you gain a simple manipulation with output data files - there is no need to merge 2 output binary files.)
http://www.mosix.org). Heterogenous cluster
with 8 CPUs, slow 10 Mb LAN; single migrated job (on 1 CPU, Cel/850 MHz),
using MVSY integrator.
mvsy_omf77_mosix0 |
1624 | run on home node, migration forbidden |
mvsy_omf77_mosix1 |
2030 | started elsewhere, migrated to the same |
mvsy_omf77_mosix5 |
1654 | the same run, but very low I/O |
The speed of migrated process is almost the same (98 %), but only for low I/O (luckily, it is a typical case for our runs).
mvsy_omf77_mosix2 |
? | 2 CPUs (Mosix threads) |
mvsy_omf77_mosix4 |
? | 4 CPUs |
mvsy_omf77_mosix6 |
5078 | 2 threads on single CPU! |
It is NOT possible to use parallel version of swift, because Mosix does not support distributed shared memory. => One have to split the calculation to several separate runs (eg. with swiftsplit script).
(However, authors of Mosix annouce the future support of DSM. Mosix cluster is now still useful for comfortable job management.)
rmvsy_mipspro_mat1 |
1550 | 1 CPU |
mvsy_mipspro_mat2 |
1725 | 2 CPUs |
mvsy_mipspro_mat4 |
? | 4 CPUs |
The run on 2 CPUs was slower due to overload of the computer.
mvsy_mipspro_hal1 |
2377 | 1 CPU |
mvsy_mipspro_hal2 |
1858 | 2 CPUs |
mvsy_mipspro_hal4 |
1228 | 4 CPUs |
The run-time on 2 CPUs is only (!) 1.3 times shorter. The performance of SMP seem to be very low on this architecture and it is much better to run single jobs.
mvs2fy_omf77_ida1 |
940 | 1 CPU |
mvs2fy_omf77_ida2 |
588 | 2 CPUs |
mvs2fy_omf77_ida1_omp |
945 | 1 CPU, -omp (without OpenMP pragma) |
MVS2FY integrator is approx. 1.7 times faster than MVSY and 2 times faster than RMVSY; one can still enlarge the timestep (upto 100 days?).
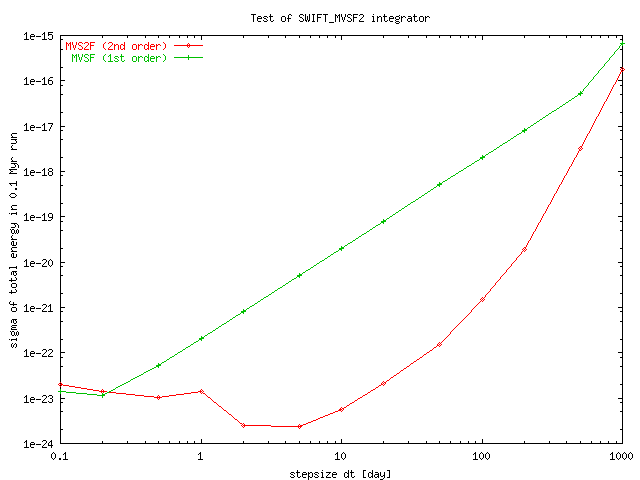
Dependence of standard deviation of total energy sigmaE on given timestep dt for integrators SWIFT_MVS2F and SWIFT_MVSF.
SWIFT_MVS2F seems to be more precise (at least by two orders of magnitude!) in a wide range of timesteps - from 2 upto 200 days.
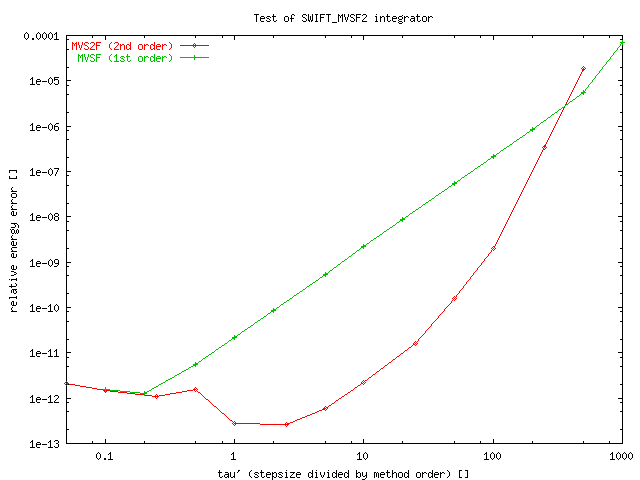
Plot relative timestep tau' - relative energy error. (tau' is timestep dt divided by method order (ie. 2), what approximately compensate higher computational expenses of 2nd order integrator MVS2F).
Usual timestep used with MVS (or RMVS3) integrator is 10 or 20 days, while we can safely use 100 days with MVS2F, keeping the same relative energy error.